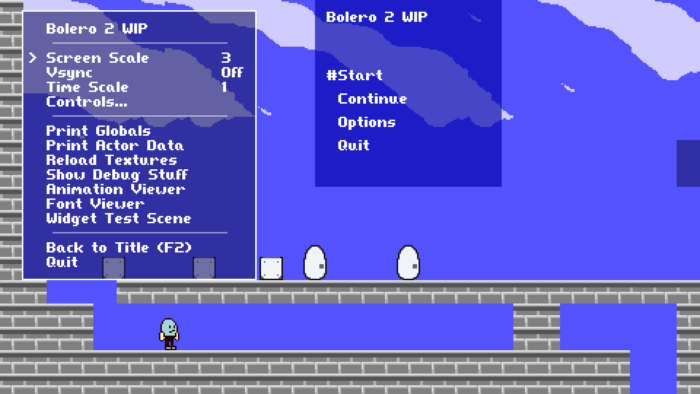
Rewriting the widget system, converting it from a pair of monolithic tick() and draw() functions, to separate source files for every widget kind. The menu on the left is running on the old widget code, and the partial menu to the right is the new system.
Work Since Last Devlog
Actors
Added a refresh rate value to actors. The higher the number, the less frequently the actor gets processed by scene.run(). There is a similar feature in ZZT and MegaZeux called the object cycle.
To go with this, I also added an option to extrapolate the display position of actors based on their XY velocity when the refresh rate is higher than 1 (that is, when they are not being updated on certain ticks.) It’s OK for small refresh gaps, but looks jittery when the gap is very wide. Position modifiers which don’t change the actual XY velocity values, such as the code that keeps actors connected to slopes, aren’t accounted for.
There’s one other thing in ZZT that I wanted to simulate. When you set multiple ZZT objects at a higher cycle, their rate of update is staggered somehow. I’m not exactly sure how it’s implemented — maybe it’s based on the location of the object in the stat order? — but it looks kind of neat. So I added a refresh_stagger variable that can simulate it.
Here is the expression for deciding if an actor is run on a tick:
(this_scene.ticks + subject.refresh_offset) % subject.refresh_rate == 0
I wouldn’t want to use this for anything that has to deal with the player directly, but it should be OK for decorative actors where collision detection isn’t critical, or which only need to be run intermittently.
Services
Last week, I added a ‘Services’ table to actors to keep track of pooled memory that needs to be released when they are removed from a scene. This week I’ve added an extra bit to the scene.run() function so that services can have a tick() call associated with them, to be run automatically before the actor’s main tick code is processed. Needs more work but it’s probably the right direction to go in.
Message Passing
I took a look at the commented-out actor-to-actor messaging code. It was something that I wrote very early on, and isn’t going to be much use now. I started over with a new source file, and made a stack structure with push/pop functions, which can also be read from start-to-end like a queue. These stack tables are included in the scene table pooling system, and are leased to actors upon being instantiated.
I have a monolithic “send” method which can push a set of values onto an actor’s stack. It can take a few different kinds of values as its destination argument, resolving them to a table if they aren’t tables already:
- Table: Assumed to be a table belonging to an actor in the sender’s scene. The sender’s scene and destination’s scene must match, or an error is generated. To have an actor push messages onto itself, use the variable self.
- Number: Assumed to be the serial number of an actor in the sender’s scene.
- String “all”: Push values onto every actor in the sender’s scene, including the sender
- String “others”: Push values onto every actor in the sender’s scene, except for the sender
- Function: Assumed to be a filter. Message will be passed to any actor in the sender’s scene that returns true when it is called as the argument of this function.
- Other strings: Assumed to be an alias. Scenes now store a table of string aliases which map to either serials of actors in the scene, or which contain the string “mailbox”.
- If the alias is a number, it attempts to send the message to an actor in the sender’s scene with a matching serial.
- If the alias is “mailbox”, then an application-wide mailbox is checked for a key matching the destination string. The mailbox contains a scene name and serial number, which would be registered ahead of time by another object wishing to get messages through this alias name.
Message processing is asynchronous by default: messages pile up in each actor stack until the scene.run() function gets around to processing the actor. Once the actor is finished reading its messages, the stack size counter is reset to zero. All actors are closed to receiving messages by default and need to opt in, and stacks are limited to a default max size.
Of these addressing modes, only string-aliases can be used to pass messages to actors across scene boundaries. Aliases can only point to one actor at a time, and they will fail to resolve to a table if the actor has been destroyed. The alias resolution is intended to let actors communicate with more abstract components without having to know anything about how they’re implemented.
Using a function as a filter allows an actor to address other actors by any value present in their table (by kind, some kind of group membership, etc).
For reading and acting on messages, the engine has two sets of global tables for this. First is a list of event definitions, with the event name being the hashmap key. The eventDef stores the number of arguments associated with the message, and a string ID of what the default handler for this event should be. The second table is a list of event handler functions.
In order to get an event or message, the actor needs to enable the event in their incoming table, and assign an event handler to the event. The default handler is used if none is specified. I’m planning on actor services setting most of these during their init calls. Two instances of the same kind can be configured to respond to a message with different handler functions.
Messages can be processed synchronously (which is to say, the message is sent, and then the recipient acts on it immediately while blocking anything else happening on the main thread), but only in cases where the sender and receiver are in the same scene. In order to prevent an application-level stack overflow, a global hard limit is imposed on the number of “send” function calls which can be active on the main thread stack at any one time.
I’m feeling pretty tempted to make group distributions for inter-scene aliases, and having a staggered message broadcast that could distribute a message to a group of actors incrementally over a longer period of time, but I should stop now until there’s a practical need for it.
States
Added a simple state system, though I’m not sure how much of this I’ll end up using. Each actor gets a stateInstance table. It holds a string value which maps to a global array of state definitions. The stateDefs contain on_enter and on_exit functions which are called whenever the current state needs to change. States can be transitioned from one to another, and they can also be pushed onto and popped off of the stateInstance. The “root” state can be changed, but not popped, so there is always at least one valid state marker assigned to an actor’s stateInstance at any time.
StateInstances all share the same data, which is the actor table. As it’s set up now, on_enter and on_exit can block transitions in certain cases, but not in others:
!: Can block transition
.: Cannot block transition
n/a: Not applicable
Change State Push State Pop State
On Exit ! n/a !
On Enter . ! n/a
The reason for on_enter not being able to block state changes is because a successful on_exit code may have already freed resources related to the old state.
A similar function can also be run against variables holding strings, without the pushing and popping part.
Widgets
I need to take the above stuff and use it to rewrite widgets, making them equal entities to actors in a scene, and breaking down the monolithic process and draw functions that drive each widget node. I’ve about hit my limit for now and need to take a break, so I’ll have to come back to it a bit later. So far I’ve got the groundwork for it down, but I need to go through the existing widget defs and port them all over to the new system.
Thoughts
So, uh, I’ve amassed a lot of firepower for shooting myself in the foot. I wanted to get these new widgets done this weekend, and made decent progress towards it, but it ultimately didn’t happen.
Looking for something else to do for a bit: I revisited MilkyTracker. A while back, I made a well-intentioned but ultimately counterproductive decision to group samples, particularly drum samples, into single instruments, with different samples mapped by octave. This just ended up making samples harder to get to. I started a new XM template file just for this game project, and imported any samples that I thought would fit in. The music I have written up to this point is way too quiet when played back in LÖVE, so I’ve adjusted MilkyTracker’s mixer volume to roughly match the output in LÖVE, and I’ve been going through all samples to normalize them and raise the gain of their ADSR envelopes.
Plans For Next Post
- Get all this nonsense working, and build proper UI interfaces for configuring the game engine from the perspective of an end user.